สร้างแพลตฟอร์ม Agentic: บทเรียนจาก Metadata Extraction ของ Box
Sep 18, 2025
สรุปแนวทางการยกระดับการสกัดข้อมูลจากเอกสารด้วยสถาปัตยกรรมแบบ agentic โดย Ben Kus, CTO ของ Box พร้อมบทวิเคราะห์เชิงเทคนิคและคำแนะนำสำหรับองค์กรที่ต้องการนำ AI มาใช้กับข้อมูลไม่เป็นระเบียบ

เพิ่งชมคลิปการบรรยายของ Ben Kus, CTO ของ Box มา แล้วรู้สึกว่าเรื่องราวการพัฒนาแพลตฟอร์มเพื่อจัดการข้อมูลไม่เป็นระเบียบ (unstructured content) ด้วยแนวคิดแบบ agentic นั้นให้มุมมองทางวิศวกรรมที่ชัดเจนและเป็นประโยชน์มากสำหรับทีมเทคในองค์กร เราจะสรุปและวิเคราะห์แนวทางของ Box ตั้งแต่ปัญหาเดิม ๆ ในการดึงข้อมูลจากเอกสาร ไปจนถึงการออกแบบสถาปัตยกรรมที่ใช้ตัวแทน (agents) ควบคุมกระบวนการ AI พร้อมข้อคิดเห็นเชิงเทคนิคและเชิงกลยุทธ์ที่น่าจะช่วยทีมงานนำไปปรับใช้ได้จริง

บทนำ: ทำไมการจัดการข้อมูลไม่เป็นระเบียบยังเป็นเรื่องสำคัญ
Box คือแพลตฟอร์มเก็บและจัดการเนื้อหาแบบไม่เป็นระเบียบที่มุ่งเน้นลูกค้าองค์กรขนาดใหญ่ มาเป็นเวลานานกว่า 15 ปี ด้วยลูกค้าที่เป็นบริษัทระดับ Fortune จำนวนมาก ตัวโจทย์ที่ Box รับผิดชอบชัดเจนคือทำให้ข้อมูลที่กระจายอยู่ในเอกสาร ไฟล์สแกน และโฟลเดอร์ต่าง ๆ กลายเป็นสิ่งที่ใช้งานได้ในเชิงธุรกิจ
เรามองว่าจุดสำคัญคือ 90% ของข้อมูลในบริษัทส่วนใหญ่ยังเป็น unstructured และการแปลงข้อมูลเหล่านั้นเป็น structured form มีประโยชน์เชิงธุรกิจอย่างมาก เช่น เปิดให้ค้นหาข้อมูล คัดกรองเอกสาร สร้าง workflow อัตโนมัติ ทำ risk assessment หรือนำข้อมูลไปใช้ในระบบบัญชีหรือระบบบริหารลูกค้าต่อได้

พื้นฐานและปัญหาที่พบก่อน generative AI
ก่อนยุค generative AI อุตสาหกรรมที่ทำงานด้านการสกัดข้อมูลจากเอกสาร (IDP, Intelligent Document Processing) มีความพยายามมานาน แต่ติดปัญหาจำนวนมาก เช่น ต้องเทรนโมเดลเฉพาะของแต่ละประเภทเอกสาร ต้องเตรียม dataset ขนาดใหญ่ ต้องพึ่ง vendor และมักจะได้ระบบที่เปราะบางเมื่อต้องขยายสู่เอกสารที่หลากหลาย
แนวทางเดิมจึงมักแนะนำให้พยายามทำให้ข้อมูลเข้าสู่ระบบฐานข้อมูลตั้งแต่ต้น แทนที่จะพยายามอัตโนมัติการสกัดจากเอกสารจำนวนมาก แต่เมื่อตลาดมีโมเดล generative (เช่น GPT-3, GPT-4 และรุ่นถัด ๆ มา) ปัญหานี้เริ่มถูกท้าทาย เพราะโมเดลเหล่านี้เข้าใจภาษาธรรมชาติได้ดีและสามารถสกัดข้อมูลจากข้อความทั่วไปได้อย่างยืดหยุ่น
ข้อจำกัดเดิมที่ทำให้การสกัดยังไม่ตอบโจทย์
เราควรหยุดสังเกตว่าปัญหาไม่ได้มีแค่ความแม่นยำของโมเดลเท่านั้น แต่รวมถึงกระบวนการทั้งหมดรอบ ๆ โมเดลด้วย เช่น การอ่านภาพ (OCR), รูปแบบไฟล์ที่หลากหลาย, ภาษาต่างประเทศ, การมีข้อมูลที่กระจัดกระจาย และความต้องการมาตรฐานความปลอดภัยระดับองค์กร
ก้าวแรกกับ LLM: ทางออกที่เห็นผล แต่ไม่พอ
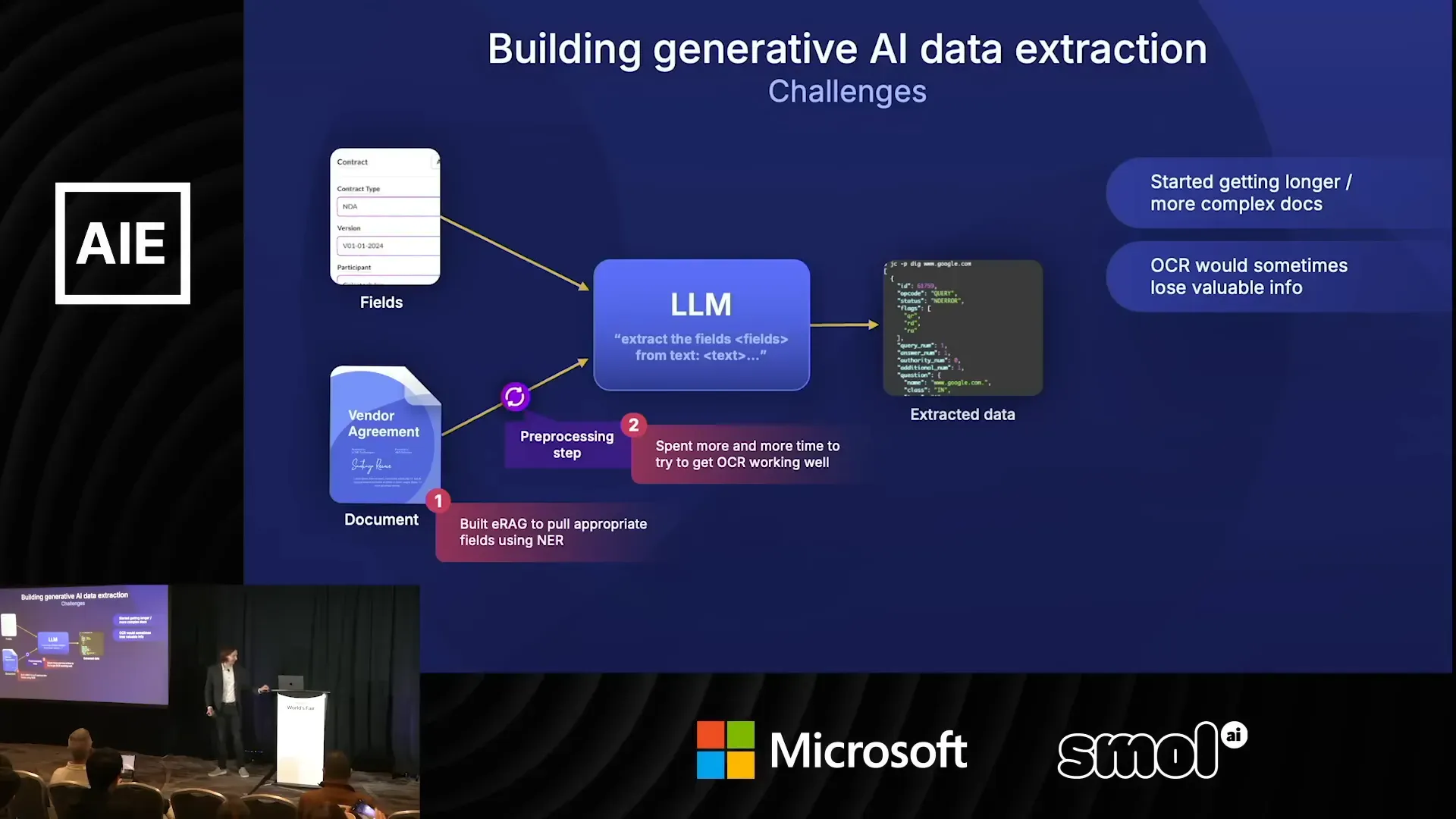
เมื่อ Box เริ่มทดลองกับ LLMs ในปี 2023 แนวทางแรกคือเตรียม preprocessing เช่น OCR แล้วส่งข้อความให้โมเดลเพื่อสกัดฟิลด์ที่ต้องการ วิธีนี้ใช้ prompt-based approach เดี่ยวหรือรีบูทด้วย few-shot prompts ผลลัพธ์น่าประทับใจในหลายกรณี โมเดลเชิงภาษาแบบสาธารณะสามารถทำได้ดีกว่าโมเดลเฉพาะมากในบางงาน
จุดเด่นคือความยืดหยุ่น สามารถรับเอกสารหลากหลายและไม่ต้องเทรนโมเดลเฉพาะมากนัก แต่ความยืดหยุ่นนี้เองก็มาพร้อมขีดจำกัด เมื่อขนาดและความซับซ้อนของเอกสารเพิ่มขึ้น เช่น สัญญายาวหลายร้อยหน้า มีฟิลด์หลายร้อยฟิลด์ หรือต้องทำ risk assessment แบบเชิงบริบท โมเดลเริ่มสูญเสียสมาธิในการตอบ และความผิดพลาดจากขั้นตอน OCR ถูกขยายออกมาเมื่อส่งข้อมูลให้ LLM
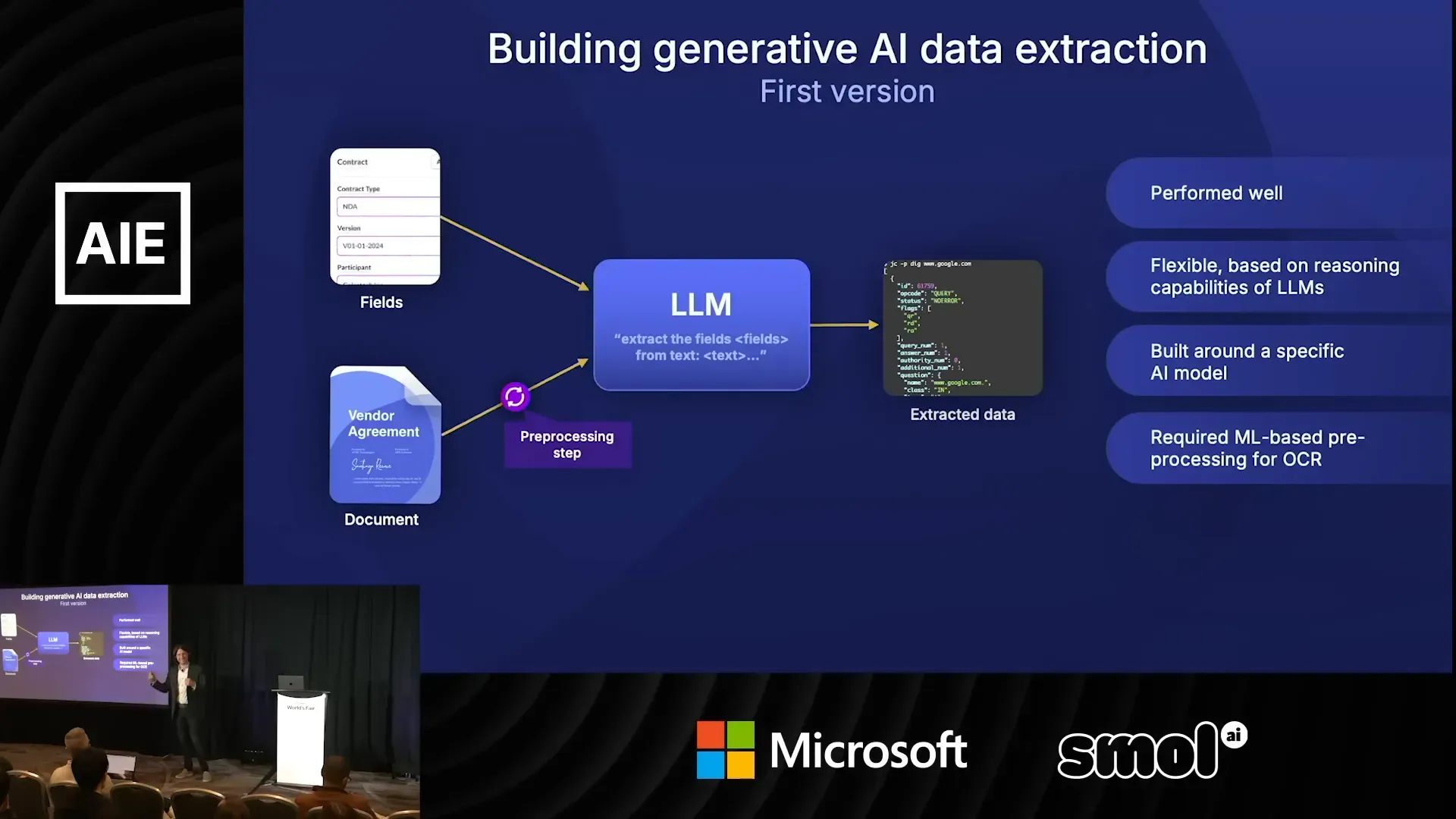
ความท้าทายเชิงปฏิบัติ
ประเด็นที่ Box เผชิญและน่าจะเป็นประสบการณ์ร่วมขององค์กรหลายแห่งมีดังนี้:
- OCR ไม่สมบูรณ์: เอกสารประเภทสแกน, ฟอร์แมต PDF ที่ฝังภาพ, หรือลายมือ ทำให้ข้อความที่ป้อนให้ LLM มีความผิดพลาดตั้งแต่ต้น
- ความจุความสนใจ (attention) ของโมเดล: เอกสารยาวมากกับคำถามจำนวนมากที่มีทั้งเงื่อนไขแยกย่อย ทำให้โมเดลหลงประเด็น
- การวัดความแม่นยำ: LLM ไม่ได้ให้คะแนนความเชื่อมั่นที่น่าเชื่อถือเหมือนโมเดล ML แบบเดิม จึงยากที่จะบอกว่า "ตรงนี้มั่นใจหรือไม่"
- ความหลากหลายของภาษาและรูปแบบ: ลูกค้าองค์กรระดับสากลต้องการรองรับภาษาต่าง ๆ และรูปแบบเอกสารที่หลากหลาย
จุดเปลี่ยน: ทำไมต้องคิดแบบ Agentic
หลังจากผ่านช่วงเวลาที่ LLM เพียว ๆ ให้ผลลัพธ์ดีในเคสง่าย แต่ล้มเหลวในเคสที่ซับซ้อน ทีมของ Box ตระหนักว่าสิ่งที่ขาดคือสถาปัตยกรรมที่สามารถผสานหลายขั้นตอนและหลายทูลเข้าด้วยกันอย่างเป็นระบบ นั่นคือจุดที่แนวคิด agentic เข้ามามีบทบาท
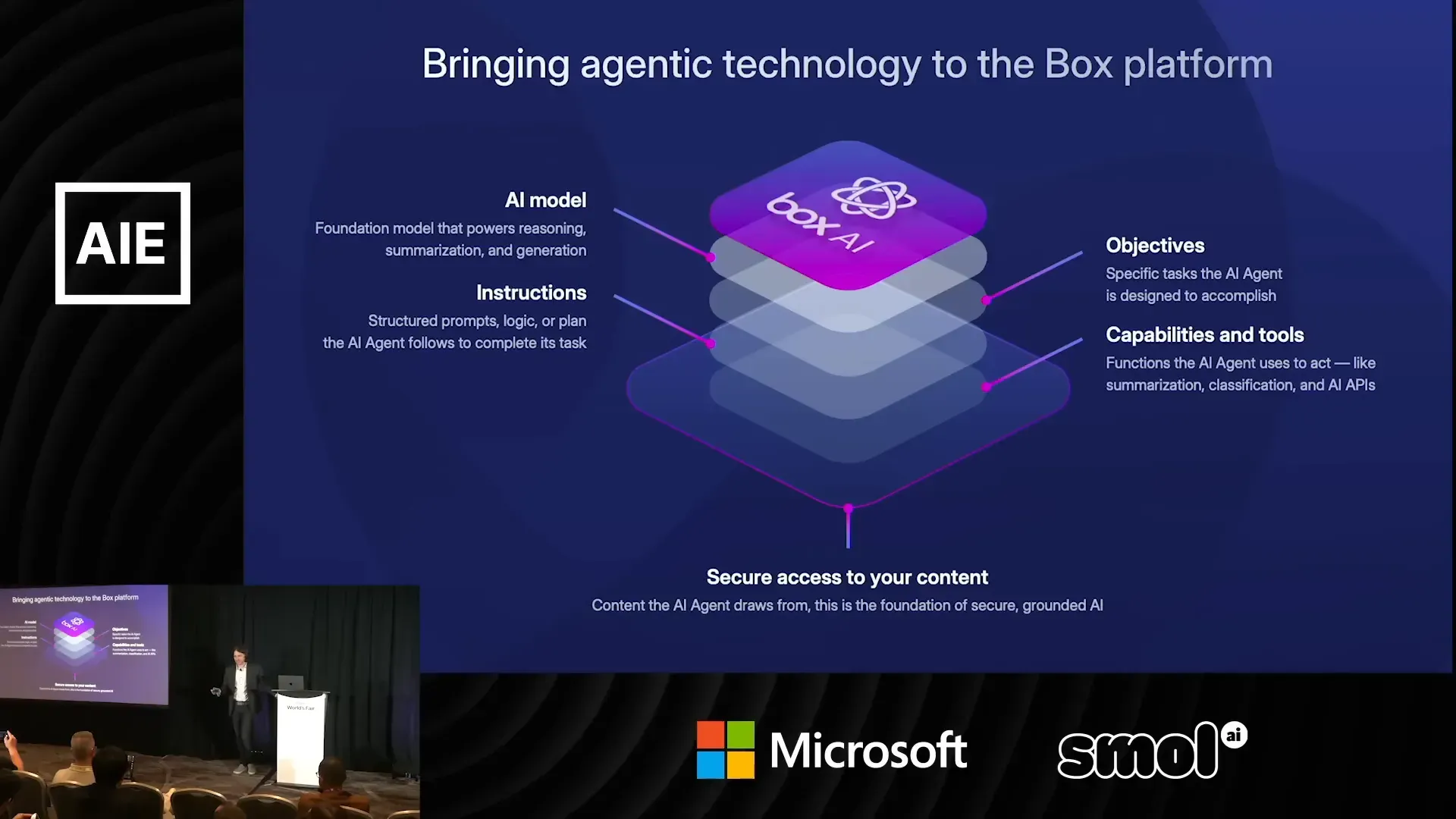
agentic คืออะไร ในมุมที่ใช้จริง
เราอธิบายสั้น ๆ ว่า agentic ในที่นี้หมายถึงการจัดเรียงการทำงานให้เป็น "ตัวแทน" ที่มีวิธีคิดหรือ objective, มี prompt/instruction, สามารถเลือกใช้เครื่องมือภายในหรือภายนอก, มีหน่วยความจำหรือ directed cache, และสามารถ orchestration ขั้นตอนตามแผนได้
จุดเด่นคือการทำงานเป็น workflow แบบ directed graph ที่แต่ละ node อาจเป็นโมเดล, เป็นการเรียก OCR, เป็นการตรวจสอบกฎ (regex) หรือเป็น module ที่ทำ voting ระหว่างโมเดลหลายตัว
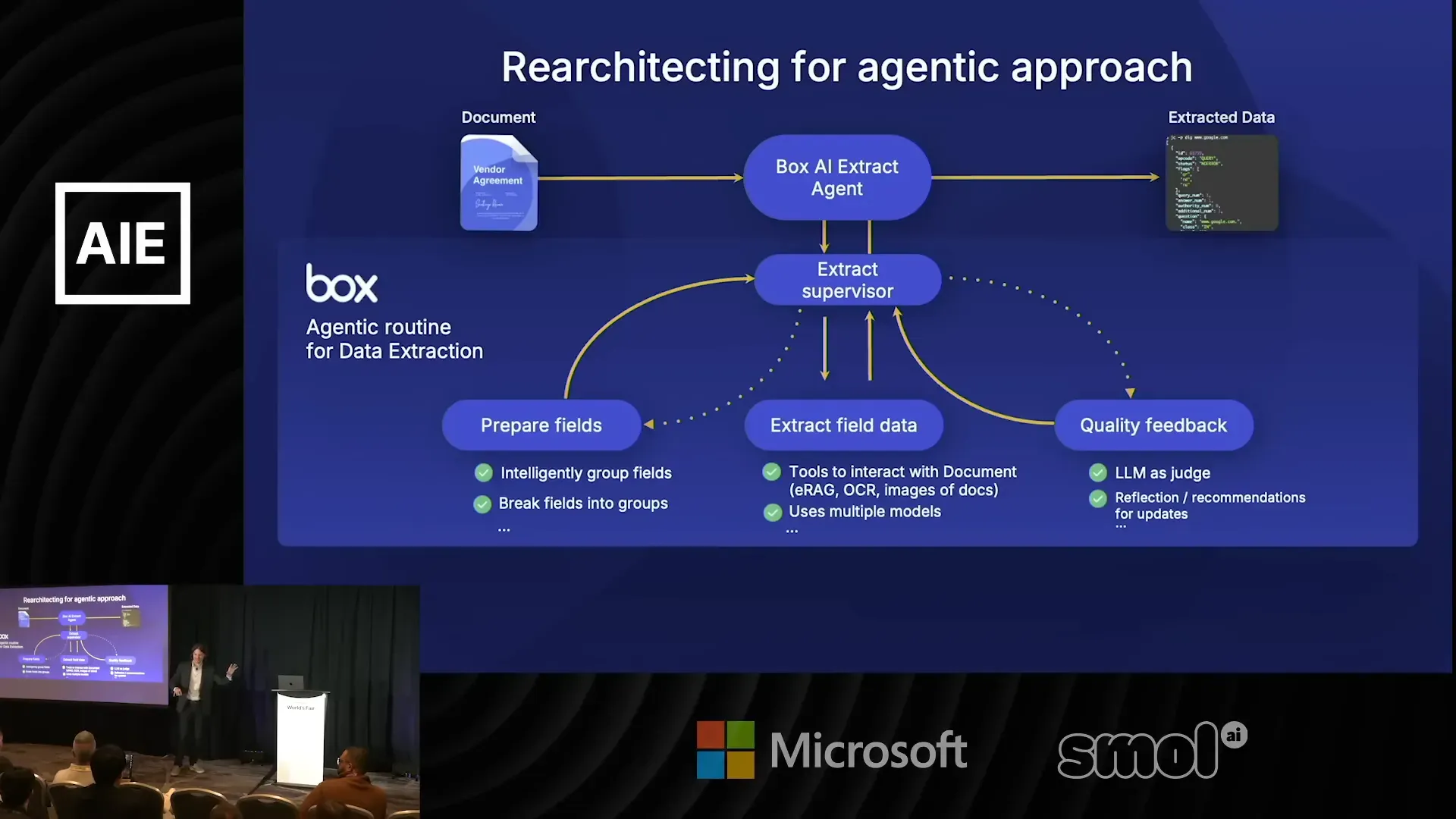
ออกแบบ pipeline สำหรับการสกัดข้อมูลด้วย agentic
จากประสบการณ์จริง ทีม Box ออกแบบ pipeline ที่ประกอบด้วยขั้นตอนสำคัญหลายอย่าง เราจะอธิบายลำดับและเหตุผลของแต่ละขั้นตอน พร้อมความคิดเห็นว่าทำไมวิธีนี้ได้ผล
1) เตรียมฟิลด์และจัดกลุ่ม (Field Preparation & Grouping)
ก่อนเริ่มสกัด ต้องกำหนดฟิลด์ที่ต้องการอย่างระมัดระวัง และจำแนกฟิลด์ที่เกี่ยวข้องกัน เช่น ฟิลด์เกี่ยวกับ "party" กับ "address" ควรอยู่ในกลุ่มเดียวกัน เพราะความสัมพันธ์ระหว่างฟิลด์ช่วยในการตรวจสอบความสอดคล้อง
ความคิดเห็น: ขั้นตอนนี้มักถูกมองข้าม แต่เป็นหัวใจของระบบที่แม่นยำ วิธีทำได้โดยการสร้าง metadata schema ที่ยืดหยุ่น เพื่อให้ agent เข้าใจความสัมพันธ์ระหว่างคีย์ต่าง ๆ
2) หลายคำถามหลายรอบ (Multi-query on Document)
แทนที่จะส่งทั้งชุดคำถามครั้งเดียว ค่อย ๆ ถามเป็นรอบ ๆ ให้ agent สำรวจส่วนที่เกี่ยวข้องก่อน แล้วจึงสกัดรายละเอียด วิธีนี้ช่วยลดภาระ attention ของ LLM และเพิ่มความแม่นยำ
ความคิดเห็น: การแบ่งปัญหาเป็น subtask ทำให้ตรวจสอบและแก้ไขได้ง่ายขึ้น และช่วยให้สามารถใช้โมเดลหลาย ๆ ตัวร่วมกันได้อย่างยืดหยุ่น
3) ใช้เครื่องมือหลายชนิดและ multi-model voting
หลังสกัดข้อมูล ทีมใช้ทั้ง OCR แบบคลาสสิก, LLM จากหลาย vendor, และ tool พิเศษ รวมถึงการให้โมเดล "vote" เมื่อคำตอบขัดแย้งกัน เช่น ให้ 3 โมเดลตอบ หาก 2 ใน 3 เห็นตรงกัน คำตอบนั้นอาจมีความน่าเชื่อถือมากขึ้น
ความคิดเห็น: การผสมหลายเทคโนโลยีเป็นแนวคิดพื้นฐานในการลดความเสี่ยงจากข้อผิดพลาดของแต่ละระบบ แต่ต้องคำนึงต้นทุนและเวลาเพิ่มขึ้น
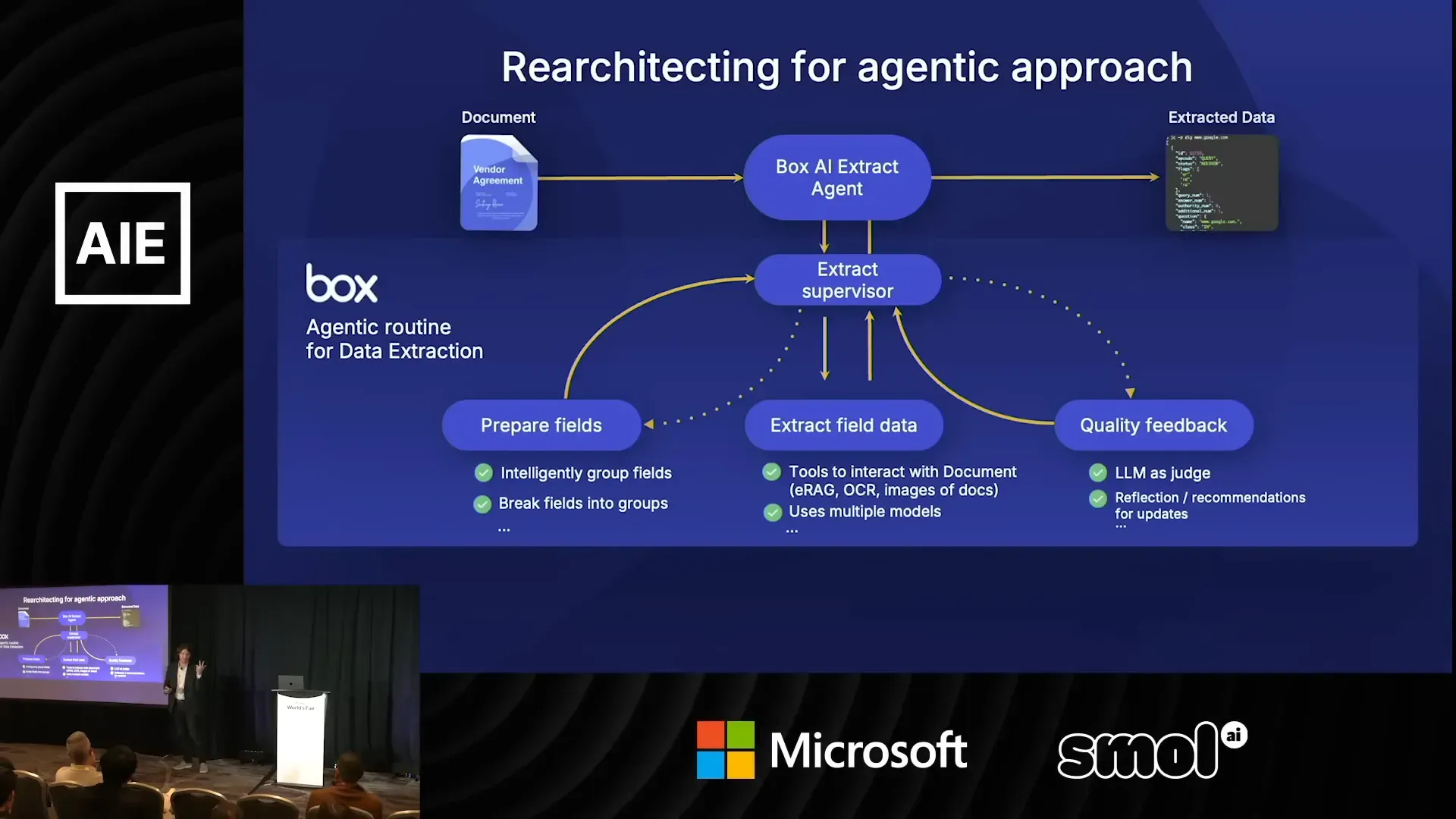
4) LM as judge — ให้โมเดลเป็นผู้ตัดสินและให้ feedback
หนึ่งในเทคนิคที่ Box ใช้คือให้โมเดลอีกตัวหนึ่งทำหน้าที่ประเมินคำตอบที่ได้ แล้วให้ feedback เพื่อลองทำรอบใหม่หากยังไม่ตรงเกณฑ์ วิธีนี้ไม่เพียงบอกว่า "ไม่แน่ใจ" แต่ยังบอกว่าควรพยายามแก้จุดไหน
ความคิดเห็น: การให้โมเดลเป็น judge ช่วยลดการต้องพึ่งมนุษย์มากเกินไป แต่ต้องออกแบบ prompt และเกณฑ์การตัดสินให้ชัดเจน มิฉะนั้นอาจได้รับ feedback ที่ไม่สอดคล้อง
5) Double-check โดยใช้ภาพต้นฉบับ
เมื่อ OCR ทำพลาด การกลับไปดูภาพหน้าหนังสือหรือ PDF ต้นฉบับและให้โมเดลตรวจสอบป้ายหรือบริบทช่วยยืนยันคำตอบได้ บางกรณีใช้การ crop ภาพส่วนที่มีคำตอบแล้วส่งให้โมเดลที่เชี่ยวชาญด้าน OCR/vision ตรวจสอบอีกครั้ง
ความคิดเห็น: การผสม vision model กับ text model เป็นแนวทางที่ชาญฉลาด โดยเฉพาะเมื่อต้องรับมือกับเอกสารสแกนหรือภาพที่มี noise
ผลลัพธ์: ทำไม agentic ช่วยได้
การยกชุดงานขึ้นเป็นตัวแทนที่สามารถ orchestration ได้ทำให้แพลตฟอร์มสามารถรับมือกับเคสซับซ้อนได้ดีขึ้น ข้อดีที่เห็นได้ชัดคือ
- ความแม่นยำโดยรวมสูงขึ้น เพราะมีการตรวจสอบหลายชั้น
- ระบบยืดหยุ่น: สามารถปรับจุดต่าง ๆ ของ workflow ได้โดยไม่ต้องแก้ทั้ง architecture
- รองรับ multi-model ได้ง่าย ทำให้ไม่ต้องยึดติดกับ vendor เดียว
- เพิ่มความสามารถในการอธิบายเหตุผลของคำตอบ (explainability) ผ่านขั้นตอนแต่ละ node

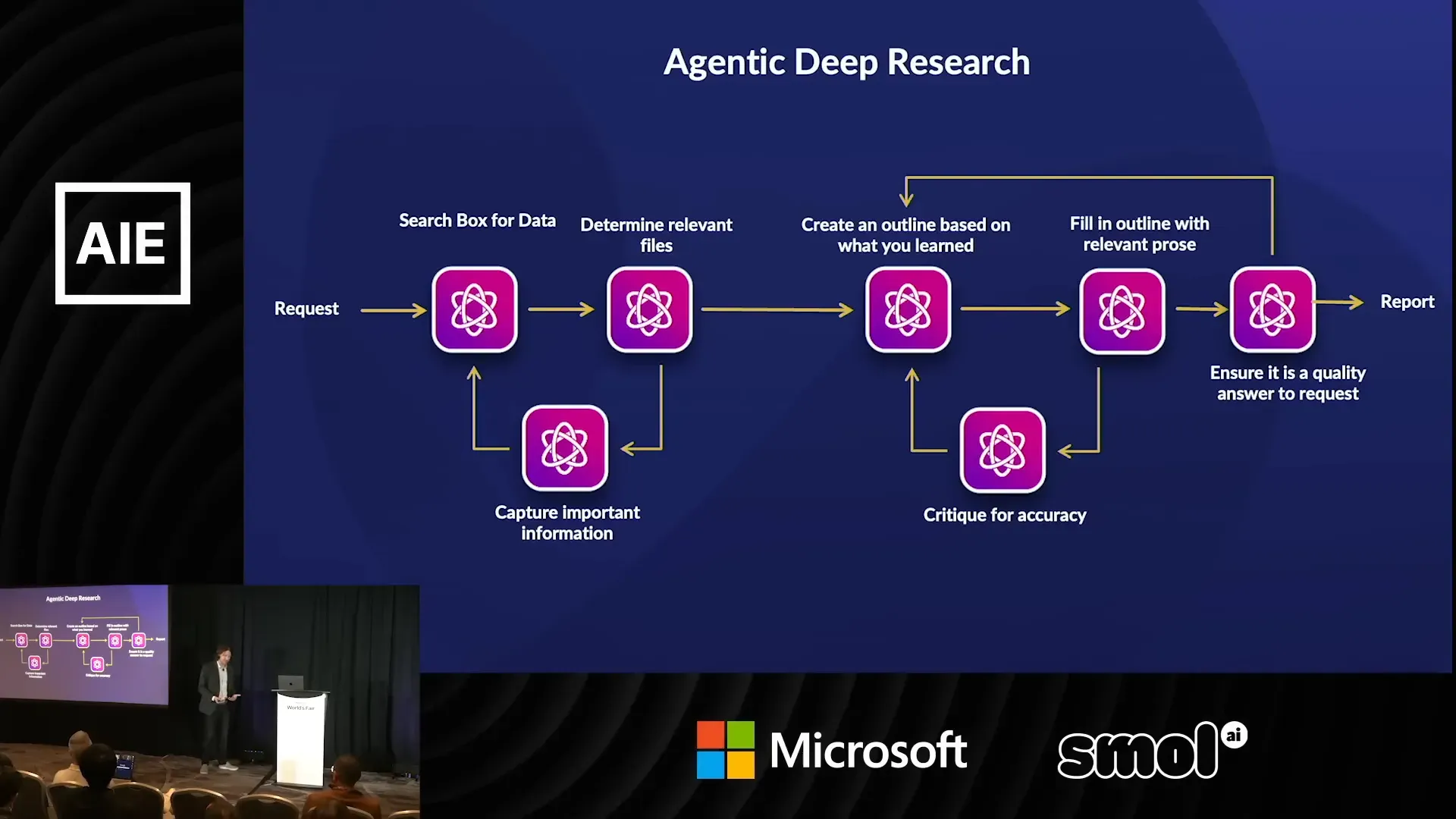
กรณีศึกษา: Deep Research บนข้อมูลภายใน
Box ใช้แนวคิดเดียวกันกับฟีเจอร์ค้นคว้าลึก (deep research) บนข้อมูลภายในองค์กร เปรียบเทียบกับการค้นข้อมูลบนเว็บโดยโมเดลสาธารณะ ความแตกต่างคือแหล่งข้อมูลเป็นเอกสารที่เป็นทรัพย์สินขององค์กร การออกแบบต้องคำนึงสิทธิ์ การเข้าถึง และความปลอดภัย
เรามองว่า deep research แบบนี้ต้องมี directed graph ที่ประกอบด้วยขั้นตอนการค้นหา สกัดข้อมูล, จัดลำดับความสำคัญ, สังเคราะห์ และสรุปผล พร้อมขั้นตอนตรวจสอบก่อนส่งคำตอบให้ผู้ใช้
บทเรียนเชิงสถาปัตยกรรมและการทำงาน
จากการเดินทางสองปี Box สรุปบทเรียนที่สำคัญหลายข้อ ซึ่งให้แนวทางกับทีมที่กำลังจะเริ่มหรือกำลังพัฒนาแพลตฟอร์ม AI ในองค์กร
แยกความรับผิดชอบ: Agentic layer vs Scale layer
เรื่องนี้สำคัญมาก โดยเฉพาะกับองค์กรที่มีปริมาณเอกสารมหาศาล ต้องออกแบบสองชั้นให้ชัดคือ
- Agentic abstraction layer: โฟกัสที่การกำกับกระบวนการโดย AI เช่น directed graphs, agents, memory, tools
- High-scale distributed system: โฟกัสการจัดเก็บ จัดทำดัชนี การทำ batch processing เพื่อรองรับปริมาณข้อมูลระดับสิบล้านหรือร้อยล้านเอกสาร
ความเห็น: การแยกระบบนี้ช่วยให้ทีมที่ออกแบบ workflow agentic สามารถทดลองได้เร็ว โดยไม่กระทบกับระบบ storage/scale หรือจำเป็นต้องเปลี่ยนสถาปัตยกรรมของทั้งองค์กรเมื่อปรับกระบวนการ
ออกแบบให้ evolve ได้ง่าย
agentic graph ทำให้การเปลี่ยน prompt หรือเพิ่ม node ใหม่ ๆ ทำได้เร็ว โดยไม่ต้อง re-architect ทั้งระบบ ยกตัวอย่างคือใน deep research เมื่อผลลัพธ์ออกมาไม่เป็นระเบียบ ทีมเพียงเพิ่ม node สรุปผลอีกตัว ปรับ prompt แล้ว deploy
ข้อคิด: ความสามารถปรับเปลี่ยนรวดเร็วเป็นข้อได้เปรียบเชิงธุรกิจ เพราะความต้องการของลูกค้ามักเปลี่ยนเร็ว
เปลี่ยนวิธีคิดทีมวิศวกรรม: Agent-first mindset
การนำ agentic เข้าสู่ทีมไม่ได้เกิดขึ้นอัตโนมัติ ต้องให้ทีมได้ลงมือสร้างและเห็นผลจริง เราเห็นว่าเมื่อวิศวกรได้สร้าง agent เล็ก ๆ ใช้งานได้ จะเกิดความคิดใหม่ ๆ เกี่ยวกับการออกแบบ API, tools และ agent-to-agent communication

นโยบายการเลือกใช้โมเดล: Fine-tuning หรือ Agentic?
คำถามยอดนิยมคือถ้า fine-tune โมเดลแล้วจะไม่สามารถแก้ปัญหาได้ไหม Box มีมุมมองชัดเจน ว่าปัจจุบันค่อนข้างไม่สนับสนุนการ fine-tune เป็นทางหลักสำหรับ use case ของพวกเขา เหตุผลหลักมีดังนี้
- ต้องตาม fine-tune ตลอดเมื่อรุ่นของโมเดลใหม่ออก ถ้ามีหลาย vendor จะเป็นภาระสูง
- agentic approach ใช้ prompt engineering และ orchestration แทนการปรับน้ำหนักโมเดล ทำให้ยืดหยุ่นรองรับหลาย vendor
- fine-tune เหมาะกับบางเคสที่ต้องการ behavior เฉพาะ แต่สำหรับการสกัดจากเอกสารที่หลากหลาย การประสานหลายเครื่องมือมีประโยชน์กว่า
ความคิดเห็น: เรามองว่า fine-tuning ยังมีที่ของมัน แต่เมื่อองค์กรต้องการรองรับหลายภาษา หลายฟอร์แมต และหลายโมเดล การพึ่ง agentic orchestration จะลดความผูกติดทาง vendor และเพิ่มความสามารถในการ evolve
การประเมินคุณภาพและกลยุทธ์การทดสอบ
Box ใช้วิธีผสมผสานหลายอย่างเพื่อวัดคุณภาพของการสกัดข้อมูล ซึ่งสำคัญมากเพราะลูกค้าองค์กรต้องการระดับความเชื่อมั่นสูง
ชุดทดสอบ (eval sets) และ challenge sets
พวกเขามีชุดทดสอบมาตรฐานและชุด challenge ที่ออกแบบให้ยากกว่าปกติ เพื่อวัดความสามารถของระบบในเคสที่ไม่ใช่ชุดคำถามมาตรฐาน
ความคิดเห็น: การมี challenge set ช่วยป้องกันการ overfitting กับเคสง่าย และเตรียมระบบให้พร้อมเมื่อผู้ใช้นำเอกสารที่ยากกว่ามาใช้
LM as judge + human feedback
วิธีประเมินอีกวิธีคือให้ LM ทำหน้าที่เป็น judge แล้วรวมกับ feedback จากผู้ใช้จริง โดยเฉพาะในลูกค้าองค์กรที่ให้ข้อมูลกลับมาเป็นค่าประเมิน คุณภาพจะดีที่สุดเมื่อผสมทั้งสองอย่าง

การออกแบบ API และแพลตฟอร์ม: API-first และความเป็นโมดูล
Box ให้ความสำคัญกับการเป็น API-first เพื่อให้ลูกค้าองค์กรสามารถเรียกใช้งาน agent ผ่าน API ได้โดยตรง ซึ่งสอดคล้องกับความต้องการในการรวมเข้ากับ workflow ขององค์กรต่าง ๆ
การออกแบบให้ agent เป็นบริการที่สามารถเรียกผ่าน API ทำให้เกิดความยืดหยุ่นในการนำไปใช้ และช่วยให้ทีมพัฒนาภายนอกสามารถสร้างเครื่องมือเสริมได้ง่าย
เครื่องมือและการเชื่อมต่อ (tools & integrations)
แพลตฟอร์มต้องรองรับการใส่ tools ที่หลากหลาย เช่น OCR engines, external DB lookups, document viewers, permission checks และองค์ประกอบ security อื่น ๆ เพื่อให้ agent ทำงานครบกระบวนการ
ความคิดเห็น: ในองค์กรที่มีข้อจำกัดด้านข้อมูล การออกแบบเครื่องมือให้รองรับ policy-aware actions สำคัญมาก เช่น agent ควรตรวจสอบสิทธิ์ก่อนดึงข้อมูลที่ละเอียดอ่อน

สิ่งที่ควรระวังและข้อจำกัดที่ยังคงมี
แม้ agentic จะช่วยแก้ปัญหาหลายอย่าง แต่ก็มีข้อจำกัดที่ต้องตระหนัก เช่น
- ต้นทุนการคำนวณ: ใช้หลายโมเดล หลายทูล ทำให้ต้นทุนสูงขึ้น
- ตอบสนองช้าลง: ขั้นตอนหลายชั้นอาจทำให้ latency เพิ่ม หากต้องการผลแบบ near real-time จำเป็นต้อง optimize
- ความซับซ้อนในการออกแบบ: Directed graphs ใหญ่ ๆ อาจยากต่อการทดสอบและดีบัก
- ข้อกำหนดด้านความปลอดภัย: Agentic ต้องมีการควบคุมการเข้าถึงและ auditing ที่ละเอียด
ข้อเสนอแนะ: ควรมีการตั้งค่าระดับบริการ (service tiers) เช่น เคสเร่งด่วนให้ path แบบ lightweight เฉพาะบางฟิลด์ ส่วนเคสต้องการแม่นยำสูงให้ path agentic ครบวงจร
แนวทางปฏิบัติสำหรับองค์กรที่ต้องการเริ่ม
จากประสบการณ์ มีแนวทางปฏิบัติที่แนะนำสำหรับทีมเทคที่ต้องการย้ายไปสู่สถาปัตยกรรม agentic:
- เริ่มจาก POC ขนาดเล็ก: เลือกเอกสารหรือเคสที่สำคัญแต่จำนวนไม่มาก เพื่อทำ proof-of-concept
- ออกแบบ schema ของฟิลด์ให้ชัดเจน: ทำให้ agent เข้าใจความสัมพันธ์และสามารถตรวจสอบข้ามฟิลด์ได้
- ทำ layered testing: มีชุด eval ปกติและ challenge sets ที่ยากขึ้น
- เก็บ feedback loop: ให้ผู้ใช้สามารถระบุความผิดพลาดและปรับปรุง prompt/agent ได้ไว
- แยกความรับผิดชอบระหว่าง scale infra กับ agentic orchestration
ตัวอย่าง workflow แบบสั้น (แนวคิด)
1) Ingest document → 2) Preprocess OCR → 3) Group fields & create subtasks → 4) Run multi-model extraction → 5) Vote & judge → 6) Re-run / check images if low confidence → 7) Return structured output + provenance
ความคิดเห็น: แนวนี้ทำให้แต่ละขั้นตอนสามารถติดตามและปรับปรุงได้ง่าย เมื่อมีข้อผิดพลาดสามารถย้อนกลับไปแก้เฉพาะจุด
คำศัพท์เฉพาะทางเพิ่มเติม
IDP (Intelligent Document Processing)
ระบบที่ออกแบบมาเพื่อสกัดข้อมูลจากเอกสาร รูปแบบดั้งเดิมมักใช้ OCR + rules + ML models เฉพาะงาน [https://en.wikipedia.org/wiki/Document_processing]
Agentic / Agent
ชั้นของซอฟต์แวร์ที่มี objective และสามารถ orchestrate ขั้นตอนต่าง ๆ โดยเรียกใช้โมเดลหรือทูลเพื่อแก้ปัญหา
Directed Graph
โครงสร้าง workflow ที่ node แต่ละ node แทน task บางอย่าง เช่น query, extraction หรือ validation ซึ่งสามารถกำหนดทางเดินการทำงานได้
LM as judge
การให้ Language Model หนึ่งตัวทำหน้าที่ประเมินคำตอบของโมเดลอื่น ๆ และให้ feedback เพื่อปรับปรุงผลลัพธ์
Eval sets / Challenge sets
ชุดทดสอบมาตรฐานและชุดทดสอบที่จะยากกว่าปกติ เพื่อวัดความสามารถระบบในระดับสูง
บทสรุปส่งท้ายจากทีมงาน Insiderly
- Agentic abstraction ช่วยให้การจัดการเอกสารซับซ้อนเป็นระบบ และปรับปรุงความแม่นยำได้มากกว่าการพึ่งพาโมเดลเดี่ยว
- แยกระบบเป็นชั้น (agentic vs scale infra) ช่วยให้ทีมทดลองและ deploy ได้เร็วขึ้น โดยไม่กระทบการจัดเก็บข้อมูลขนาดใหญ่
- อย่าเริ่มด้วย fine-tuning เป็นทางหลัก เมื่อต้องรองรับหลาย vendor และหลายภาษา ให้พิจารณา orchestration ด้วย prompt และ multi-model
- การออกแบบ schema และ grouping ของฟิลด์เป็นหัวใจของผลลัพธ์ที่ใช้งานได้จริง
- ต้องมีการวัดผลเชิงรุก โดยใช้ชุดทดสอบมาตรฐานและ challenge sets ควบคู่กับ feedback จากผู้ใช้จริง

บทสรุปจาก Insiderly
มุมมองโดยรวมคือ agentic architecture ไม่เพียงเป็นเทคนิคใหม่ แต่เป็นวิธีคิดที่จะเปลี่ยนวิธีการออกแบบระบบ AI ในองค์กร โดยเฉพาะเมื่อต้องจัดการกับข้อมูลที่ไม่เป็นระเบียบและซับซ้อน เรารู้สึกว่าองค์กรที่ยังลังเลอยู่ควรเริ่มทดลองกับ POC ในงานสำคัญ ไม่จำเป็นต้อง scale ทันที แต่ต้องออกแบบให้ modular เพื่อปรับปรุงต่อเนื่อง
สรุปแล้ว agentic เป็นเครื่องมือที่ทรงพลังเมื่อนำมาใช้ร่วมกับวิธีการที่รัดกุม เช่น schema design, eval sets, multi-model orchestration และการควบคุมความปลอดภัย ขอให้ทีมเทคลองคิดแบบ agent-first และแยกความรับผิดชอบของ infrastructure ให้ชัด เพื่อให้การยกระดับเป็นไปได้จริงในเชิงธุรกิจ
อ่านฟรีให้ตามทัน สมัครสมาชิกเมื่ออยากตัดสินใจให้คมขึ้น
บทความเปิดให้อ่านได้ตามปกติ ส่วนสมาชิกจะได้ brief เชิงลึก คลังย้อนหลัง และมุมวิเคราะห์สำหรับใช้คุยงานกับทีม
